
Security Information and Event Management (SIEM) systems are used for collecting data from your entire network or enterprise environment. By scanning logs and other data from across your system, they then can analyze the event data to help determine security threats potentially facing your organization, so your security teams can appropriately prevent and respond to threats. By providing insight into log data in real time, event management SIEM tools can help boost your data security and prevent costly issues down the line.
As I’ll explore in this article, using a SIEM system helps ensure your compliance obligations are met, customer data is carefully protected, and any issues can be remedied quickly before they affect your end users. For these purposes, I recommend SolarWinds® Security Event Manager as a high quality, real-time SIEM tool with easy-to-use features, simple configuration, and the ability to integrate with many other applications and other security software.
Jump ahead:
Top 10 SIEM Best Practices
Getting Started with SIEM Software
7 Common SIEM Use Cases
There are many specific SIEM use cases requiring the use of SIEM systems to help ensure the best outcome—because taking an automated, focused approach is essential with both general threat intelligence as well as meeting compliance requirements for your business. In this guide, I’ll outline how and why you should consider implementing a SIEM solution into your environment and some of the most common use cases in which having a SIEM tool could benefit you.
When you’re using a SIEM tool, you can set up correlation rules for threat detection matching the issues you may expect to see. A correlation rule means when your logs are fed into your SIEM system, certain sequences of security events are correlated with anomalies or unusual behavior in your network. You can set up correlation rules to trigger an alert if a certain condition is met, such as a certain number of log files being generated within a particular amount of time.
A number of SIEM correlation use cases will be familiar to you, as most of them relate to particular compliance rules and measures needing to be followed with regard to sensitive data.
For many organizations, your top 10 SIEM correlation rules should be in line with all or many of the below 7 use cases, which means you may need to set correlation rules to flag an alert for unusual log behavior, track changed access privileges for certain accounts, and perform other critical monitoring.
Take a look at the following SIEM use cases to help make sure you’re supporting a comprehensive security analytics process in your business and to determine which use cases may apply to you.

- HIPAA: The Health Insurance Portability and Accountability Act (HIPAA) requires patient data to be protected with physical, security, and network security measures. HIPAA compliance requires unique user IDs, data encryption, and decryption processes to be used. Organizations are also required to follow appropriate reporting processes when it comes to auditing for hardware and software activity. From a SIEM perspective, security processes need to be in place to detect whether all data subject to HIPAA is being protected properly. This could mean setting up alerts for when data is inappropriately accessed or if a system breach occurs.
- GDPR: The General Data Protection Regulation (GDPR) is a major European data privacy law requiring the private data of European citizens to be protected in certain ways. For example, private data must not be shared with third parties and must also be stored securely. In addition, organizations are also required to maintain a Personal Data Breach Register, which means you need a tool to notify you if any data breaches have occurred.
- PCI: Payment Card Industry (PCI) compliance is another situation in which you can use a SIEM tool, as credit card information is also subject to many security compliance requirements. First, cardholder data must be protected through secure systems and strong access control measures, as well as regular monitoring, testing, and reporting. PCI compliance measures are similar to HIPAA compliance because users should have unique user IDs and data needs to be protected both physically and in terms of network and user access.
- Insider Threats: Most organizations have external threats in mind when they think of attacks and data breaches, but preventing insider threats is another major use case for SIEM tools. Users who have access to sensitive or private information should be carefully chosen and protected, and no user should be given more access to data than they need to do their jobs. Users with broad access could accidentally change, move, or delete important files, or could inadvertently see private customer data such as in the above PCI, GDPR, and HIPAA compliance use cases. Protecting against accidental and malicious insider threats is a core feature of SIEM systems.
- Privileged Access Abuse: On a similar note, privileged access abuse is another reason why organizations should use SIEM tools. If a malicious attacker gains access to your systems, administrator accounts or those with high levels of access are commonly targeted. Keeping an eye on system access, privileges, and account behavior is important for preventing privileged access abuse before it occurs.
- Threat Hunting: SIEM tools can also help you perform general threat hunting and identification processes, since they can alert on unusual events, accounts behaving in a strange way, or high numbers of unusual logs. This can help indicate the start of an attack, or an account or program has been compromised, before the data breach or loss occurs.
- General Security: For general security purposes, SIEM tools are useful in tandem with firewalls to protect from outside threats and work well with access rights management tools to protect sensitive data from inside access.
Top 10 SIEM Best Practices
Once you have your tool set up, you need to follow several best practices to ensure your software works in the most effective way.
- Sufficient Scope: To make sure your SIEM tool works efficiently, you should always plan and scope your security needs. Complete a thorough analysis to determine primary risks, decide which systems, users, networks, and applications are in scope for monitoring, and consider which parts of your business or data are highly sensitive. With proper scope you can make sure everything vital is being monitored, without large amounts of unnecessary data collection.
- Appropriate Correlation Rules: Set up your correlation rules as discussed above, to link in with whatever your security risks are. For example, if you have major HIPAA compliance needs, your correlation rules should be set up for common SIEM alerts relating to HIPAA issues, to notify you of problems with health data access and storage.
- Audit and Compliance Requirements: To ensure your scope and correlation rules are always correct, maintain an up-to-date record of what your compliance requirements are. A member of your legal, audit, or IT team should always have a clear idea, for example, of what PCI compliance measures you need to undertake, and should be on top of any legal or regulatory changes affecting your business.
- Proper Deployment: When you choose your SIEM tool, it won’t be much use if it isn’t properly deployed. Make sure you have all the necessary infrastructure and operating equipment setup. In addition, conduct thorough site preparation to ensure deployments will go as smoothly as possible.
- Test Run: Take some time to make a test run of your SIEM tool, before you have to use it in the real world. An administrator or a member of your IT team can write some small scripts to test the SIEM tool (such as purposefully creating unusual logs or access patterns) to see if everything is working properly. This is an opportunity to fine tune correlation rules or SIEM software configurations.
- Constant Monitoring: For SIEM software to be effective, you need to be collecting data constantly, so it can build a pattern of what normal behavior looks like. Baselining your system helps SIEM tools detect anomalies, while constant monitoring ensures unusual log behavior isn’t accidentally missed.
- Access Rights Management: When you’re working with sensitive data, SIEM should be a “last line” defense instead of the first step. Use access rights management tools to ensure nobody has access to information they shouldn’t be able to see. Sensitive information should be carefully protected, and any temporary access should be revoked as soon as the user no longer needs access. Check out my in-depth review of SolarWinds Access Rights Manager solution, which is leading the access rights market.
- Other Security Tools: Alongside SIEM and access rights management tools, you should also set up other security tools such as firewalls and malware detectors. By using all these tools together, you can set up a comprehensive security system to flag issues quickly, allowing you to troubleshoot or protect sensitive data before a breach occurs.
- Comprehensive Response Plan: If an attacker gets through your systems, or an unknowing employee accidentally gains access to confidential information, you need to set up a response plan, so any issues can be quickly remedied. Ensure you have a plan with the relevant people named, escalation processes detailed, and troubleshooting approaches laid out. This will ensure any breach is minimized.
- Regular Review: Finally, a regular review of all the above processes and systems should take place. Check whether your SIEM system is deployed properly, your infrastructure is appropriate, and your systems are optimized for best performance. In addition, keep all other security tools updated and configured correctly.
Getting Started With SIEM Software
Once you decide you’d like to use a SIEM tool to help improve your security posture, you’ll need to set the tool up to work in line with SIEM alerts best practices to make sure you get the most out of your SIEM system.
The best SIEM tool on the market I’ve found to help ensure you can set up detailed alerts and effectively monitor for the above use cases is SolarWinds Security Event Manager (SEM). SEM includes several pre-built connectors allowing it to gather log files from numerous different locations across your systems. This means SEM can build a complete picture of your network and allow you to easily detect threats, meet audit requirements, and review logs in a centralized location.
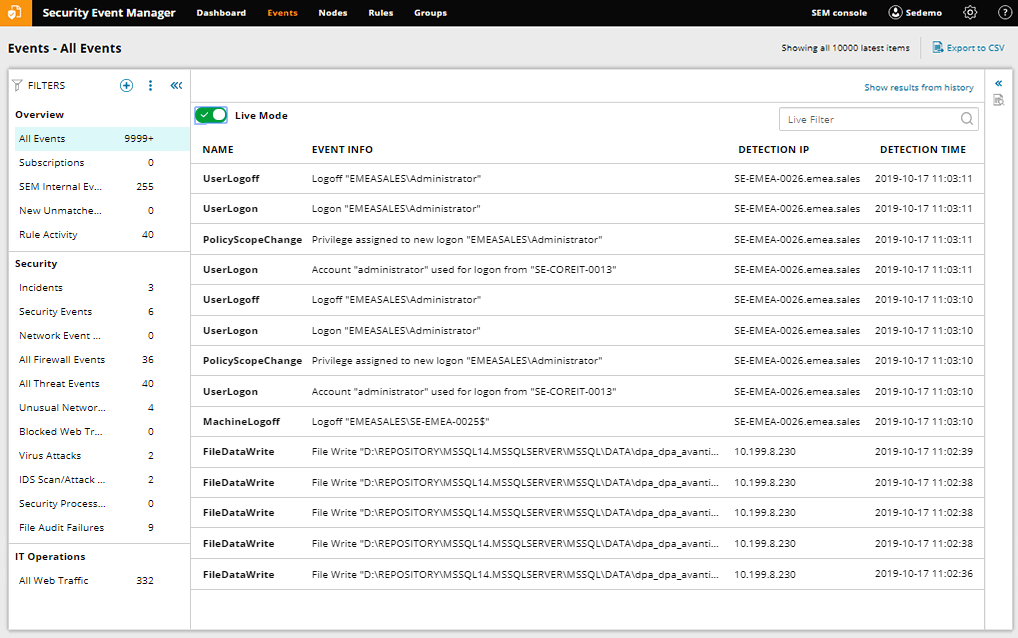
In addition, SEM includes several compliance reporting tools, with out-of-the-box reports to help you comply with requirements for HIPAA, PCI DSS, SOX, ISO, DISA STIG, FISMA, FERPA, NERC CIP, GLBA, GPG13, and many more.
One of its great features is automated threat responses, as it can respond quickly with pre-set actions if certain conditions are met. So, if a correlation rule is triggered, not only will you be notified with an alert, but SEM can take its own pre-set action to minimize the damage caused by the breach.
It also includes tools to perform an analysis of your files and access rights, so you can determine if suspicious permission changes have occurred in relation to files, folders, and registry settings. This helps to defend against insider threats. This, in combination with its USB device monitoring and log analysis, means SEM is a comprehensive security tool capable of helping protect your enterprise against both internal and external threats. The best part is you can try it risk free with by downloading a free trial of SEM for 30 days.